I admit to intentionally being slow on the AI train. Immediately seeing where it could be useful in terms of efficiency and automation, I stubbornly held to an ideal that I trust my human brain more than a mega big-data cruncher. While many tasks can and should be automated where possible, I strongly believe that work is not only about outcomes, but the process too – especially in language learning. If all communicative work is done by an AI bot, is anyone really having a conversation?
I still do most of my work 100% human. This article was for example not drafted or edited by ChatGPT as I want the authenticity of my own voice and my thought process to organise the writing. As AI usage becomes a norm of editorial work, my habits will likely change, but I’m sticking to principles for now.
Yet a curious person will eventually dive even into the developments they are wary of, and in my case that means looking for value in language learning – a realm where I really doubted its value. After a bit of experimenting, now I am doubting myself instead.
In this article I test using ChatGPT in an integral part of my language learning process instead of my long-term method, which relied heavily on online context dictionaries. There is nothing conclusive here, but there are a myriad thoughts and questions along the way.
To explain how ChatGPT really shakes my process up, I need to start with the old-school approach.
A tested method failing?
For years I have maintained a tried-and-tested method for building up my vocabulary in new languages. It’s not glamourous but it’s effective. It’s not flashy but does rely on flashcards.
The problem is this. Although I find this approach to still be effective, it also appears to be becoming less efficient. I’m going to share this process, and then look at what happens when ChatGPT gets added into the mix.
The basic process looks like this. Over the years I have accumulated focus vocabulary lists, designed to get me speaking as soon as possible. I then work on the first 1000 words or so from frequency lists. I find contextual sentences for each word and phrase, and by the end of it I have a base in the language without ever having seriously worried about grammar rules.
Input these sentences into a digital flashcard deck, study 10 a day, and in three months I have vocabulary to cover most everyday situations, and a toolkit of phrases for maintaining conversations and building more knowledge using the target language itself. Focussing on the toolkit phrases first lets me start speaking within a couple of weeks.
That is how I quickly build a useable base that gets me immediately into conversations. The process works well for developing that base too, but the initial intention is to build as useable base as quickly as possible. Looking at Anki, the open-source flashcard software I use and recommend, I apparently have accumulated over 25,000 cards in the 8 years or so I’ve been using it…and that doesn’t take into account the thousands I’ve deleted.
That is a lot of information.
Believe it or not, keeping up my flashcards costs only about 20 minutes a day. The wonder of spaced repetition keeps input manageable and effective.
Setting up the flashcards, however, and building up materials for new projects can take much longer. These vocabulary lists that build the base of my flashcards need to be filled in, with context that is both useful and understandable. Just having a list of words isn’t learning a language – it’s learning a bunch of new sounds expressing the same meanings. Language needs context. Context also solidifies the meaning of words, making them easier to remember anyway – memorising word lists is the road to madness (been there, my A level days involved hiding in a room and reading out thousands of German words repeatedly. It’s not that effective, and the people around you will think you’re weird).
How do you find words in contextual sentences then?
Online there are a series of ‘context dictionaries’. Websites like ‘Reverso’ and ‘Linguee’ have been my staples for years. Using these, I input a word from my list, and get a bunch of real use sentences with the word in it. Once I have sentences for the words on my list, they become flashcards and learning becomes effortless.
Warning – you will end up with targeted ads in every language under the sun inputting hundreds of words into these dictionaries. My favourite was the ad for a Chinese takeaway in Reykjavik. No, I haven’t tried learning Icelandic yet. I can only assume looking up lyrics in Faroese caused that advert to appear.
So let’s take the word “context” as an example, sticking with Chinese. Perhaps a bad choice, as translating “context” is contextually a bit fiddly for Chinese…but anyway. For the sake of this example, I’ll take the word 方面 (fangmian).
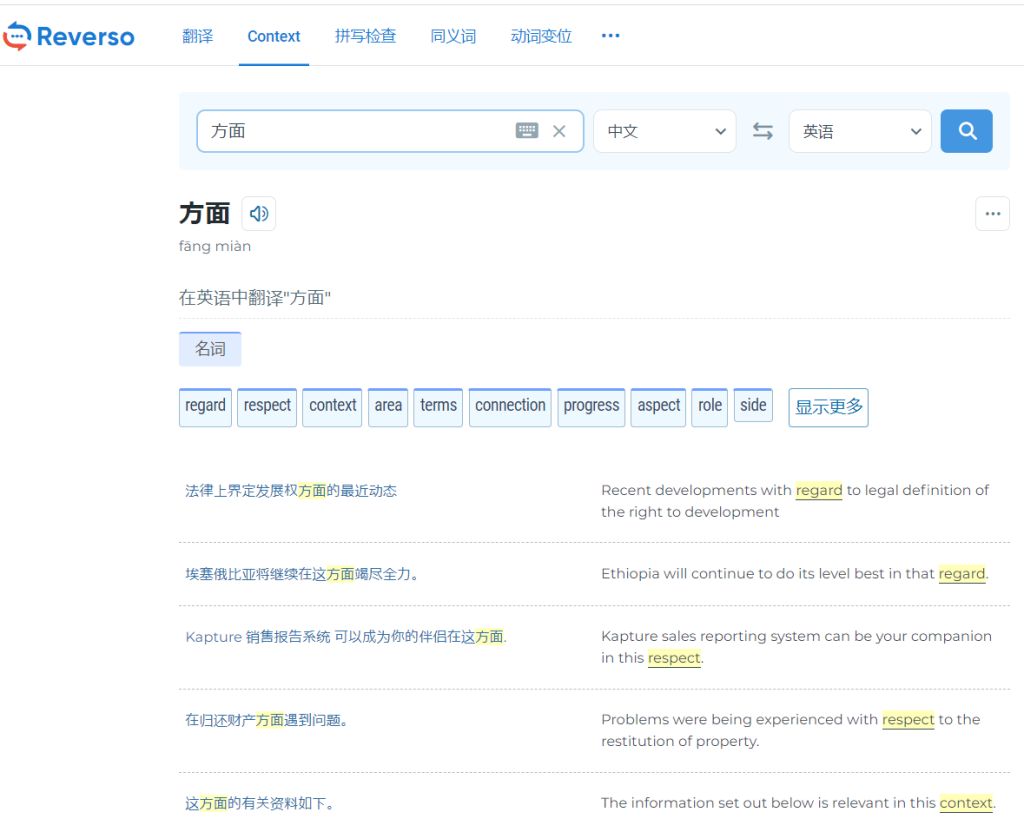
I’ve inputted 方面, and Reverso gives me a whole list of sentences with it in. I can look through these, find one I think is a great example, and use it in my flashcards. In this case, I would probably go for the bottom one. It’s (relatively) simple and it is used in the context I want.
Now I would move onto another word, rinse and repeat.
This has worked for a long long time. Problem is twofold though. Firstly and most obviously, filling in the lists takes a while to setup, and to be frank can get really dull. Secondly is an emerging problem – these context dictionaries seem to be getting worse over time
The sentences they return tend to be scoured from the internet and quality control seems to be going downhill – perhaps because there is too much data available to ensure the good stuff gets prioritised.
Where I used to be able to easily get nice, simple sentences which were perfect for learning new vocabulary, more and more outputs are coming from technical manuals and arcane looking reports – not useful context sentences when I don’t understand what it’s saying in English either. This varies from language to language, as each language not surprisingly must draw from different sources.
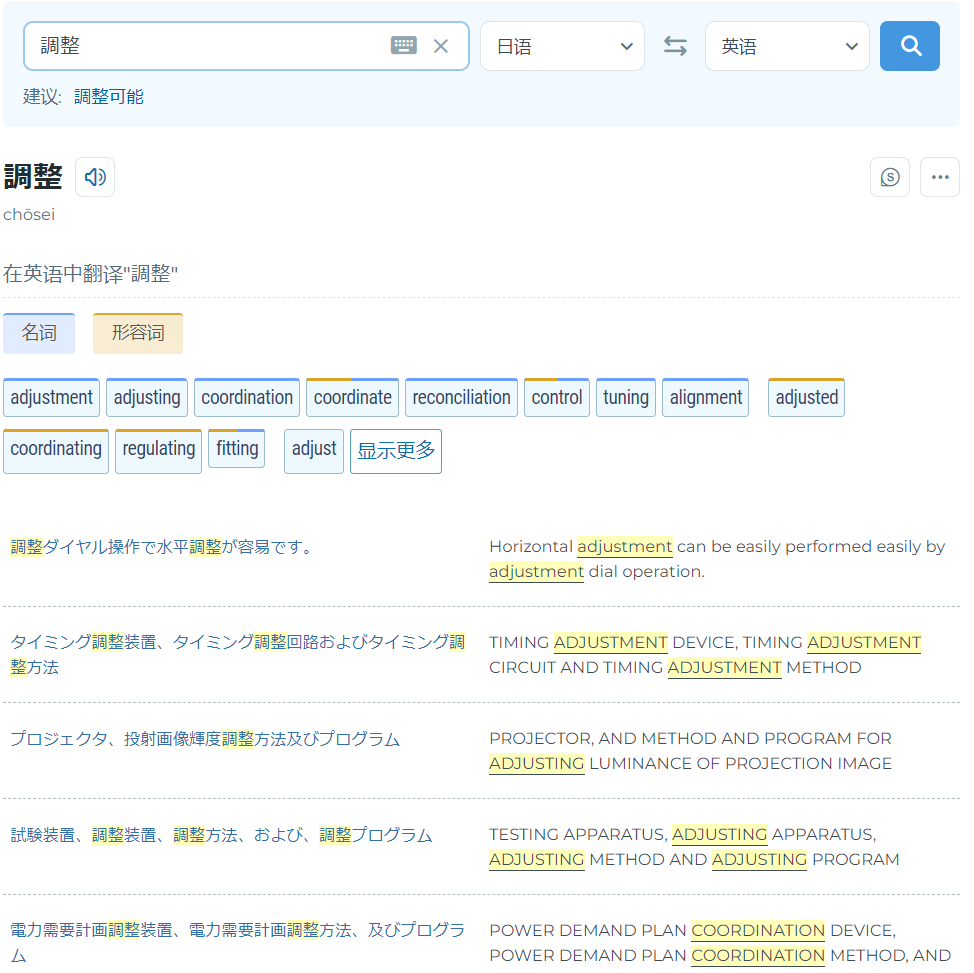
One reason for the apparent sliding quality in outputs could of course be my own word needs – as you advance in a language the vocabulary becomes A) less common and B) more technical. So if I need an example for something like the Japanese word for “adjust” (調整する – chōsei suru), is it really that surprising the example sentences are too technical to be good examples?
In any case, after a point it becomes really hard to get any useable content for the cards – an existential crisis for my long-preferred learning method.
What if I could reliably get simpler sentences, without having to scour through unusable examples? Enter ChatGPT…
Can ChatGPT do better?
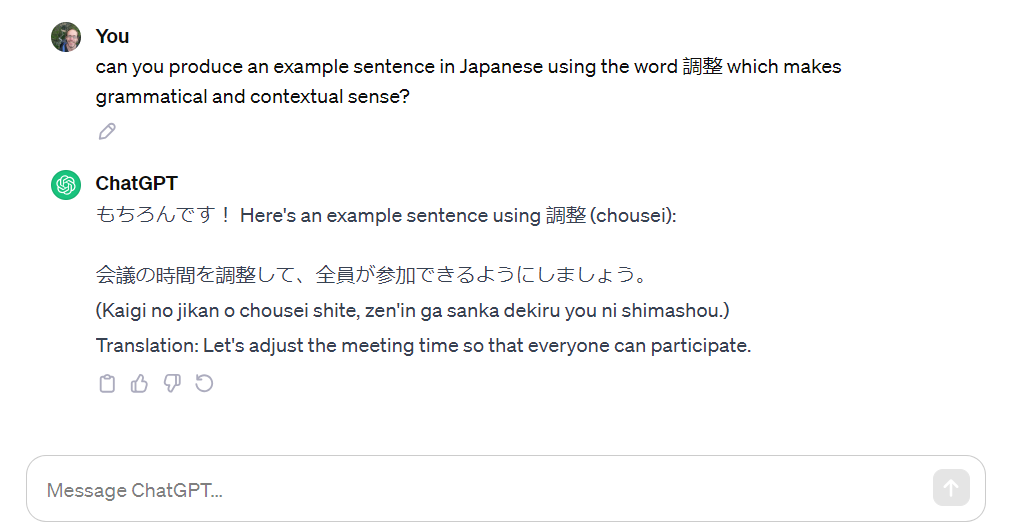
Here was my first attempt at prompting ChatGPT for my context sentences.
ChatGPT successfully gave me a reasonable sentence, while calling me a lazy student. Impressive.
My main concern with using ChatGPT is that it will – I believe – generate a sentence from scratch, while the context dictionary method takes real sentences. A real sentence acts as a guarantee that the word is used correctly. Remember when Google Translate was new and it regularly produced gibberish? That was my concern with ChatGPT.
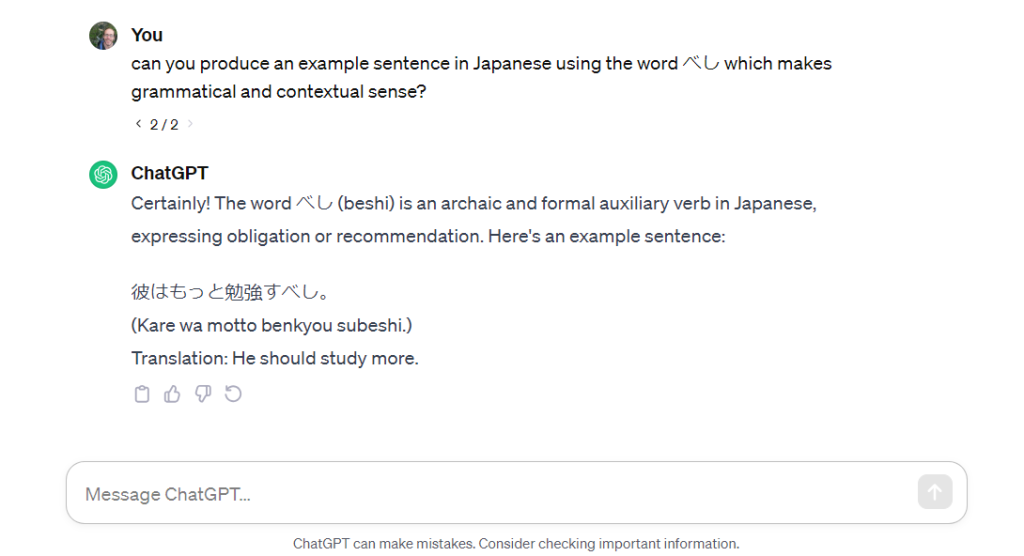
This sentence looks good though. べし is a bit archaic for the sentence, but ChatGPT even points that out.
Let’s see how it deals with 調整, seeing as Reverso did a poor job:

It does – and it pains me a little to say this – better than Reverso. Admitting that my Japanese is not perfect and I’m far from an expert of good written style in Japanese, this sentence makes sense and at least to me looks grammatically correct.
I instinctually feel there would probably be a better way of phrasing the sentence than using the annoyingly wordy しなければなりません(shinakerebanarimasen) suffix, (the first way many Japanese learners learn to express “must do”) but I did prompt for ‘grammatically correct’, not ‘aesthetically pleasing’.
So let’s assume for a second that I didn’t like the output. What happens if I run the prompt again?
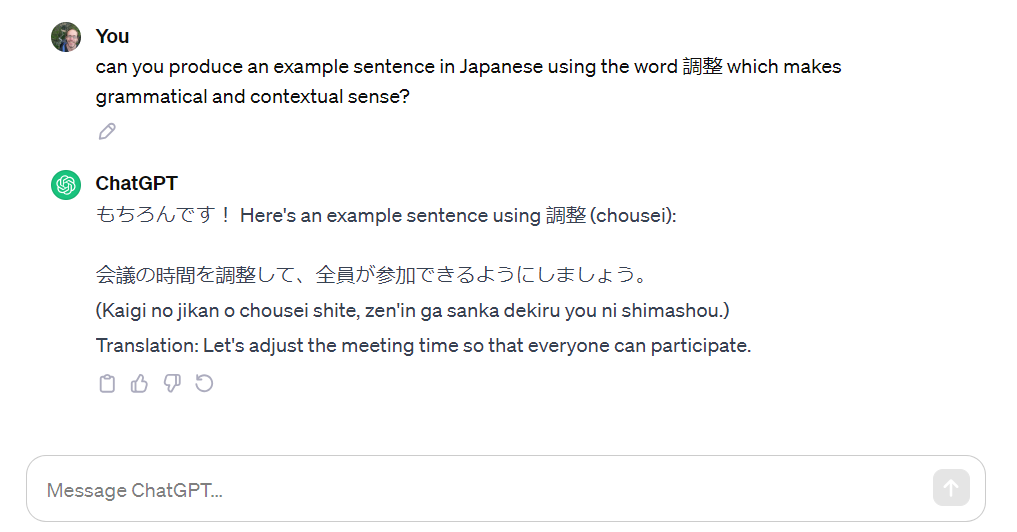
It gives me another sentence that to my eyes looks pretty good and is definitely clear enough for practice purposes.
Maybe if I were to use German for this experiment, a language I trust myself more to identify issues with, my view would be different…but ChatGPT seems to do a better job than the dictionaries. Perhaps experiments with German can be a future article.
A dilemma
So I’m presented with a dilemma.
Playing around with ChatGPT showed me that it is indeed capable of creating valuable language resources, seemingly more user-friendly than databases of real language use. There are important questions though.
The example sentences ChatGPT produced for me were pretty good, but it was a small sample. There is no guarantee that it will remain consistent.
In the old method where I scoured through sentence databases, I knew that the sentences would be real-use and that was a key benefit of the approach. Just because a sentence makes grammatical and contextual sense, it doesn’t necessarily work semantically. I fear AI will produce sentences that ‘work’ but are plain weird to native speakers. Over time this could build bad habits when it comes to producing a target language.
Even if the context sentence search method is slow compared to ChatGPT prompting, you have to look through multiple example sentences until you see one that works for you. The result is more contextual input. Of course, you can prompt ChatGPT repeatedly and get different examples, but there is a benefit to having multiple options on one page and comparing them collectively.
Now we have some more philosophical considerations. Language is about human communication. This is a gift I just frittered away to a computer. While the context dictionary method relied on a computer database, the sentences themselves originated from creative human beings. With the ChatGPT method, that is lost. It becomes computer generated.
There is a tension here between efficiency and humanity. As a language enthusiast who dodges round the label ‘linguist’ to avoid people thinking I like syntax trees and talking about split-ergatives, I love languages for their value in connecting people and ways of life. While efficiency is important in a learning process – my flashcard method developed to be efficient – the whole learning process should not be entirely outcome led.
Ways to develop this experiment
There is a lot more to delve into with how ChatGPT can be used for language flashcard generation. In the examples above, I had a relatively simple prompt which I did not change. Adjusting this could drastically affect outputs. For example…
I could try demanding ChatGPT keeps a whole phrase within its output rather than just a word. This could be especially useful for the first week in a new language, where I personally focus on ‘conversation-guiding’ phrases, phrases that can keep you going in a conversation when you hardly know any of the language and help you discover more. Seeing as repeatedly prompting ChatGPT gives new outputs, it could be really interesting to see if answers change for phrases with one example clearly in most common use. If I re-prompt ChatGPT for a phrase expressing ‘I can’t’, will it give me ‘I am not able’, ‘This is beyond my control’ and ‘I must verily step down from this challenging opportunity’? Probably not, but it’s worth playing with.
I could request it gives me five examples instead of one, from which I could pick my favourite for the flashcards. This would confer the advantage of comparison provided in the context dictionaries back to AI prompting. If this were then combined with a script to input immediately into a flashcard program, you could build an introductory language course flashcard deck in an evening.
ChatGPT recognised that the Japanese word 調整 can mean ‘adjustment’ and it can mean ‘regulation’. Can I request it gives me an example for specific translations of the word? How about two different examples with the word in different usages? Beginner language learners can fall into the trap of believing that each word has its corresponding word in other languages, but it doesn’t work like that. Words represent ideas and phenomena, and these do not neatly match up from language to language. This means a good language learning method needs to consider variation in word use, instead of assuming ‘this word’ = ‘that word’. A weakness of flashcard approaches is that it can reinforce the idea that one side of the card is equal to the other side, but having examples with varying meanings helps mitigate that.
I could also make weird requests. I asked for a sentence which made grammatical sense – what if I intentionally ask for non-sensical sentences? How about a sentence with exactly one intentional grammatical mistake? This could be fun for testing the limitations of ChatGPT’s language generation prowess. It could also be used to quickly generate practice questions – you could create a card asking ‘what’s wrong with this sentence?’ and there would be a guaranteed error to find.
What next?
ChatGPT produces better language content that I expected. At least with my prompts so far, it has generated clear, useable language that seems to be relatively accurate. Considering one of the most common uses of ChatGPT so far has been as an editing tool, we should hope that it produces accurate language output…but I remained sceptical until testing it.
This idea can really be stretched a lot further and I will be writing on it again soon, but at the back of my mind is this challenging question – how much of a role should AI play in human communication and nascent language learning?
I expect this to be a deep rabbit hole. Let’s fall in.